Многонишково програмиране с Python#
План на лекцията:
Скалиране от 1 към много
Какво е нишка ?
Работа с нишки (Threads)
Python GIL
Threads, round 2
“Многопроцесност”
asyncio
Примери
Скалиране от 1 към много#
Нека се върнем към едни по-прости времена - когато процесорът (да го наречем “v1”) може да изпълнява една-единствена задача. Нека освен този прост процесор, да имаме и набор от задачи - [t1, t2, t3].
Процесорът взима първата задача, изпълнява я, взема втората задача, изпълнява нея, и така докато не мине през всички задачи.
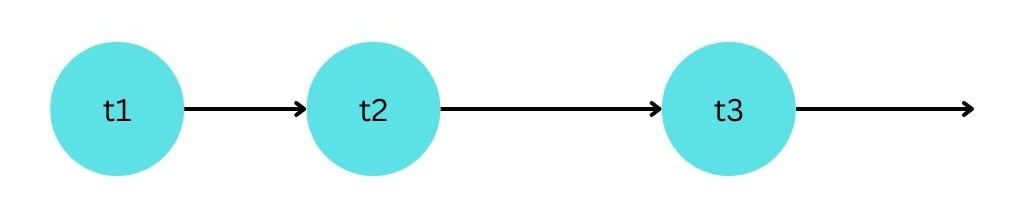
Нека си представим, че задачата t2 отнема повече време, защото трябва да изчака за някакъв ресурс (например файлова операция). В това време, нашия процесор v1 чака, и не прави никакви изчисления. Това със сигурност не е оптимално.
Какво е конкурентност ?#
Нека да вземем един нов, по-добър процесор (“v2”), който може да разпознае кога даден процес чака за ресурс, и в такава ситуация да даде приоритет на друг процес.
В тази ситуация, когато t2 чака за ресурс, процесорът може да пусне t3 по-рано. Когато ресурсът на t2 стане наличен, процесорът ще спре t3, и ще даде време обратно на t2.
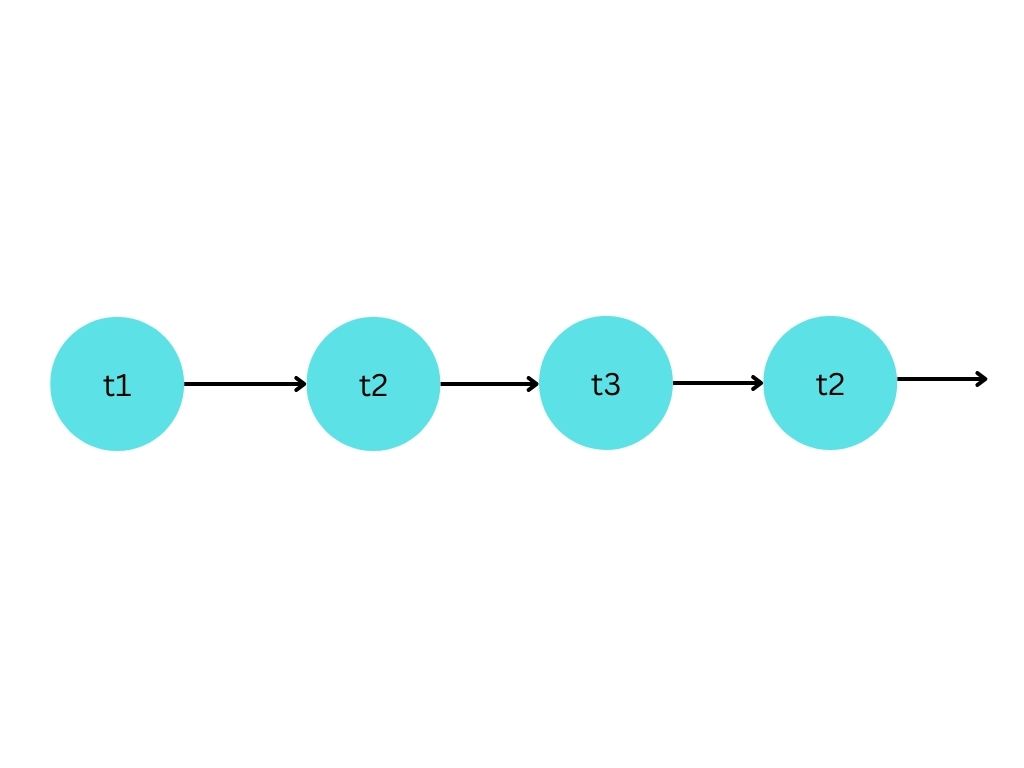
Това изпълнение, ни позволява да изпълним задачите си по-бързо - вместо да чакаме t2 да приключи, това време в чакане може да се използва за изпълнението на t3.
Този модел на изпълнение, в който изпълнението на следващата задача не е нужно да изчаква приключването на текущата, се нарича “конкурентно изпълнение”. Важно е да се отбележи, че конкурентното изпълнение не е едновременно (паралелно) изпълнение на задачи - продължаваме да изпълняваме по една задача в даден момент, просто редът им не е детерминиран. Ние не знаем в какъв ред ще се изпълнят задачите и коя от тях ще бъде изпълнена първа.
Какво е паралелизъм ?#
Колкото и оптимално да е раздаването на процесорно време от нашия v2 процесор, той все още не може да прави паралелни изчисления. Затова нека въведем нашия “v3” процесор - той ще е два v2 процесора “залепени” един за друг. Това би означавало, че нашия v3 процесор може да изпълнява две задачи едновременно (паралелно).
Модерните процесори#
Модерните процесори са изградени от няколко ядра (8, 10, 16), които могат да изпълняват различни задачи паралелно. В идеалния свят, ако нашата задача отнема t време на 1 ядро, то на n ядра, би трябвало да отнеме t/n време.
Какво е нишка ?#
Нишката може да бъде разглеждана като най-малката смислена поредица от инструкции, които да бъдат изпълнени. Един процес съдържа една или повече нишки. Нишките могат да комуникират една с друга, с помощта на споделена памет или с т.нар. канали.
Съществуват два вида нишки - нишки на ядрото (kernel threads) и потребителски нишки (user threads). Нишките на ядрото са менажирани от kernel-а - той се грижи за предаването на изпълнението от една нишка на друга. Kernel нишките споделят една и съща памет и файлови ресурси. Всяка нишка обаче има собствен стек, копие на регистрите и специална памет за конкретната нишка.
User нишките (наричани още “зелени” нишки, green threads) се управляват на ниво потребителски процес. Ядрото на ОС не знае за тяхното съществуване. Факта, че те се оправляват от потребителски процеси, прави предаването на контрола между всяка от тях евтина операция (от гледна точка на kernel-а, няма смяна на изпълняващата се нишка, съответно няма context switch). Главния недостатък на user нишките е при изпълнението на блокиращи операции (най-често свързани с IO операции) - при такава операция, вместо да се блокира само една нишка, се блокира целия процес.
Съществуват три модела за работа с нишки, определяни от съотношението на брой kernel threads към user threads
1:1 - в този модел, на всяка нишка създадена от потребителя съотвества на kernel нишка
N:1 - в този модел, всяка нишка създадена от потребителя се съпоставя към една kernel нишка
M:N - в този модел, M на брой потребителски нишки се съпоставят към N на брой kernel нишки
Работа с нишки (Threads)#
За работа с нишки в Python използваме библиотеката threading. Тя ни предоставя различни инструменти за стартиране, синхронизиране и обща работа с нишки.
Основният клас с който ще работим, е класът Thread. Той има за цел да се погрижи за изпълнението на дадено парче питонски код, в отделна нишка. Можем да зададем кода, който искаме да изпълним по два начин - като Callable обект, подаден на конструктора на Thread, или като създадем собствен клас, който да наследи Thread и да презапишем run метода.
За да стартираме нишка, трябва да извикаме start метода - той има за цел да подготви нова нишка, в която да бъде изпълнено съдържанието на run метода.
from threading import Thread
def hi():
print("Thread with a Callable in the init")
t1 = Thread(target=hi)
t1.start()
class MyThread(Thread):
def run(self):
print("Custom Thread class")
t2 = MyThread()
t2.start()
Thread with a Callable in the init
Custom Thread class
Тук е важно да се отбележи, че когато наследяваме от Thread, не трябва да предефинираме никакви други методи, освен __init__ и run. Можем да добавяме нови методи, но не трябва да променяме поведението на останалите методи в Thread.
from threading import Thread
from time import sleep
def delayed_hi():
sleep(2)
print("Overslept a bit... hi")
t1 = Thread(target=delayed_hi)
t1.start()
print("The early bird gets the worm")
The early bird gets the worm
Overslept a bit... hi
В горния пример, изпълнението на програмата продължава напред със следващите редове код. Програмата ни приключва тогава, когато всички нишки за приключили работа.
Ако искаме да изчакаме дадена нишка да приключи преди да продължим с изпълнението на кода, можем да използваме метода join.
from threading import Thread
from time import sleep
def delayed_hi():
sleep(1)
print("I'm a thread")
t1 = Thread(target=delayed_hi)
t1.start()
print("The thread has started")
print("I want to wait for it to end")
t1.join() # Comment this, to see the change
print("The thread has finished")
The thread has started
I want to wait for it to end
I'm a thread
The thread has finished
Методът join спира изпълненето на кода, докато нишката не приключи работата си или не срещне Exception. Възможно е да подадем timeout параметър на join - той индикира колко време да изчакаме нишката да приключи. Важно е да отбележим, че след изтичането на timeout параметъра, нишката може да продължи да работи. С методът is_alive можем да проверим дали дадена нишка все още работи.
from threading import Thread
from time import sleep
def sleepy_thread():
print(">Going to sleep")
sleep(20)
print(">Did a really good nap")
t1 = Thread(target=sleepy_thread)
t1.start()
print(f"Is the thread working ? {t1.is_alive()}")
print("Let's give it some time")
sleep(2)
print("Time to get up !")
t1.join(timeout=3)
print(f"Is the thread working ? {t1.is_alive()}")
t1.join()
print(f"What about now ? {t1.is_alive()}")
>Going to sleep
Is the thread working ? True
Let's give it some time
Time to get up !
Is the thread working ? True
>Did a really good nap
What about now ? False
Друга важна особеност на Thread, е че ако нашата функция връща някакъв резутлат, той няма да ни бъде върнат, ако функцията се изпълнява през thread.
from threading import Thread
def return_a_value():
return 5
t1 = Thread(target=return_a_value)
res = t1.start()
print(f"{res=}, {type(res)=}")
res = t1.join()
print(f"{res=}, {type(res)=}")
res=None, type(res)=<class 'NoneType'>
res=None, type(res)=<class 'NoneType'>
Нека разгледаме следния практически пример - имаме следната функция, която изчислява (до някаква степен) безкрайна сума. Като пример, ще вземем следната сума $\( \sum_{k=0}^{\infty} \frac{99^k}{(99(k+1))^{97}} \)$
Можем да напишеш функция, която изчислява част от реда - с начално \( k_{start} \) и крайно \( k_{end} \)
import math
def calculate_partial_sum(start: int, end: int) -> int:
sum = 0
for k in range(start, end + 1):
numerator = (99 ** k)
denominator = (99 * (k+1)) ** 97
sum += numerator // denominator
return sum
Нека изчислим първите 24000 члена на този ред
import time
start = time.time()
calculate_partial_sum(0, 24000)
end = time.time()
print(f'The call took {(end-start):.2f} seconds')
The call took 13.06 seconds
Забелязваме, че кода ни отнема ~13 секунди да пресметне първите 24000 члена да реда. В този си вариант, членове на реда не зависят един от друг - това ни позволява да ги пресмятаме на интервали, които можем да пуснем на няколко нишки.
Нека като първи пример пуснем две нишки - едната да изчисли първите 12000 члена, а втората, останалите.
import time
from threading import Thread
t1 = Thread(target=calculate_partial_sum, args=(0, 12000))
t2 = Thread(target=calculate_partial_sum, args=(12001, 24000))
start = time.time()
t1.start()
t2.start()
while t1.is_alive() or t2.is_alive():
time.sleep(0.1)
end = time.time()
print(f'The 2 threads took {(end-start):.2f} seconds')
The 2 threads took 14.82 seconds
Забелязваме, че на две нишки, кодът ни се изпълни за ~15 секунди - изненада. Нека пробваме на 4 нишки, каква е ситуацията.
import time
from threading import Thread
t1 = Thread(target=calculate_partial_sum, args=(0, 6000))
t2 = Thread(target=calculate_partial_sum, args=(6001, 12000))
t3 = Thread(target=calculate_partial_sum, args=(12001, 18000))
t4 = Thread(target=calculate_partial_sum, args=(18001, 24000))
start = time.time()
t1.start()
t2.start()
t3.start()
t4.start()
while t1.is_alive() or t2.is_alive() or t3.is_alive() or t4.is_alive():
time.sleep(0.1)
end = time.time()
print(f'The 4 threads took {(end-start):.2f} seconds')
The 4 threads took 21.37 seconds
С 4 нишки, нещата стават още по-бавни… Какво се случва ?
Python GIL#
Една от особенностите на Python, е т.нар. global interpreter lock (GIL) - накратко, само една нишка може да работи с интерпретатора на Python в даден момент. Това е направено с цел, да се реши проблема с промяната на променлива от една нишка, докато друга я достъпва. (По-конкретно, проблемът може да се появи, когато дадена памет трябва да се освободи, след като в едната нишка се стига до порция от кода, в който променливата вече не се използва).
Съществуването на GIL в Python улеснява писането на код - нашия код винаги е thread-safe (няма как две нишки да се борят за един и същ ресурс). Освен това, GIL позволява използването на C библиотеки, които не са предвидени за работа в многонишков режим.
Наличието на GIL в Python обаче означава, че нашия “многонишков” код всъщност не е многонишков - да, ние стартираме няколко нишки, но те се изпълняват конкурентно, а не паралелно. На практика това означава, че при задачи, в които разчитаме единствено на операциите на процесора, кодът ни ще се държи все едно се изпълнява на една нишка.
Това обаче е вярно за задачи, които са изцяло зависими от процесора - както казахме по-горе, понякога нашите задачи трябва да “чакат” за някакъв ресурс (например файл) - тогава интерпретатора ще отнеме контрола на чакащата нишка, и ще го предаде на следвщата нишка чакаща време за изпълнение. На практика това означава, че използването на нишки в Python би донесло подобрение във времето за изпълнение, независимо от GIL.
Ситуации в които това би било вярно, е когато работим с GUI - през повечето време нашата програма няма да прави CPU изчисления, и активната нишка ще е тази, върху която се изпълнява графичния интерфейс. Друг пример, е когато имаме задачи с много IO операции - писане или четене от файлове.
Ако искате да научите повече детайли за GIL, може да разгледате тази статия, или този клип.
Threads, round 2#
Освен начини за създаване на нишки, в threading библиотеката се намират и полезни инструменти за синхронизация между нишки. Синхронизацията между нишки представлява механизми, които осигуряват правилната работа със споделени ресурси между няколко нишки.
Семафори#
Първият обект който ще разгледаме, е семафорът. Семафорът съдържа брояч, който ако е по-голям от 0, позволява на дадена нишка да влезе в т.нар. критична секция (да достъпи споделен ресурс между нишки). С влизането в тази критична секция на една нишка, брояча се намаля с 1. Когато една нишка излезе от критичната секция “връща” семафора (увеличава неговия брояч с 1). Ако друга нишка стигне до тази критична секция, и брояча на семафора е 0, нишката ще трябва да изчака докато брояча е отново по-голям от 0.
В Python, семафора е реализиран в Semaphore класа. Той съдържа два основни метода - acquire и release. acquire метода проверява дали брояча е със стойност по-голяма от 0. Ако е така, намалява брояча с 1 и продължава напред. Ако брояча обаче е със стойност 0, изчаква докато брояча не стане > 1. release метода пък увеличава стойността на брояча с 1.
Ще разгледаме следния пример - имаме две нишки, всяка от която ще пише в общ списък. За да гарантираме, че във всеки даден момент само една нишка ще пише в списъка, ще използваме семафор.
import threading
def add_another_item_to_list(item: int, items: list[int], semaphore: threading.Semaphore):
print("Waiting to write in the list")
semaphore.acquire()
items.append(item)
semaphore.release()
print("Wrote successfully in the list")
semaphore = threading.Semaphore(1) # Стойността подадена в конструктора е началната стойност на брояча на семафора
items = []
t1 = threading.Thread(target=add_another_item_to_list, args=(1, items, semaphore))
t2 = threading.Thread(target=add_another_item_to_list, args=(2, items, semaphore))
t1.start()
t2.start()
print(items)
Waiting to write in the list
Wrote successfully in the list
Waiting to write in the list
Wrote successfully in the list
[1, 2]
Можем да използваме семафори и да подсигурим, че една нишка ще се изпълни преди която и да е друга. Нека този пъти имаме 3 нишки, и искаме да подсигурим, че нишка 1 ще се изпълни винаги преди 2 и 3.
import random
import threading
def add_another_item_to_list(item: int, items: list[int], semaphore: threading.Semaphore, is_first_thread: bool = False):
print(f"Waiting to write {item} in the list")
if not is_first_thread:
semaphore.acquire()
items.append(item)
semaphore.release()
print(f"Successfully wrote {item} in the list")
semaphore = threading.Semaphore(0) # Стойността подадена в конструктора е началната стойност на брояча на семафора
items = []
t1 = threading.Thread(target=add_another_item_to_list, args=(1, items, semaphore, True))
t2 = threading.Thread(target=add_another_item_to_list, args=(2, items, semaphore))
t3 = threading.Thread(target=add_another_item_to_list, args=(3, items, semaphore))
threads = [t1, t2, t3]
random.shuffle(threads)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(items)
Waiting to write 3 in the list
Waiting to write 2 in the list
Waiting to write 1 in the list
Successfully wrote 1 in the list
Successfully wrote 3 in the list
Successfully wrote 2 in the list
[1, 3, 2]
Event#
Нека разгледаме следната ситуация - имаме N на брой нишки, като първата от тях трябва да изпълни някакъв код, преди да могат да продължат другите. За цел синхронизация, трябва да имаме механизъм, чрез който всичко освен първата нишка да изчакат, докато първата нишка не каже че е приключила.
Един начин по който можем да имплементираме това е със специален флаг - докато флага има стойност False, нашите нишки няма да се изпълняват. Когато флага стане True, имаме зелена светлина за изпълнението на останалите нишки.
Python ни предлага удобен механизъм за решаването на този проблем - Event класа. Той разполага със следните методи:
is_set()- проверява дали флага е със стойностTrueset()- задава стойност на флагаTrueclear()- изчиства стойноста на флага (задава се стойностFalse)wait()- блокира текущата нишка, докато флага не станеTrue
Нека разгледаме примера, в който една нишка ще направи някакви изчисления, ще ги запази в променлива, а друга нишка ще използват тази стойност.
import threading
import time
constant = 0
def calculate_variable(event_signalizer: threading.Event):
print("Calculating the variable...")
time.sleep(1)
global constant
constant = 42
print("Done !")
event_signalizer.set()
def other_calculations(event_signalizer: threading.Event):
print("Starting other calculations...")
event_signalizer.wait()
result = constant ** 2
print(f"The result is {result}")
event = threading.Event()
t1 = threading.Thread(target=calculate_variable, args=(event,))
t2 = threading.Thread(target=other_calculations, args=(event, ))
t1.start()
t2.start()
t1.join()
t2.join()
Calculating the variable...
Starting other calculations...
Done !
The result is 1764
“Многопроцесност”#
https://docs.python.org/3.10/library/multiprocessing.html#module-multiprocessing
Един начин да заобиколим GIL-а, е да използваме множество процеси - така всяка задача има собствен Python интерпретатор (съответно и собствен GIL). multiprocessing библиотеката предоставя подобни на threading функции, чрез които можем да реализираме истинска паралелност.
Process#
Можем да стартираме нов процес, като инстанцираме обект от тип Process - той работи по същия начин както Thread класа.
from multiprocessing import Process
def hello_from_the_other_side(name: str):
print(f"Hello, {name}")
p1 = Process(target=hello_from_the_other_side, args=("Lyubo", ))
p1.start()
p1.join()
Hello, Lyubo
Нека повторим примера с пресмятането на реда от по-горе, но този път ще използваме Process обекти, вместо Thread такива.
import math
def calculate_partial_sum(start: int, end: int) -> int:
sum = 0
for k in range(start, end + 1):
numerator = (99 ** k)
denominator = (99 * (k+1)) ** 97
sum += numerator // denominator
return sum
import time
start = time.time()
calculate_partial_sum(0, 24000)
end = time.time()
print(f'The call took {(end-start):.2f} seconds')
The call took 12.72 seconds
import time
from multiprocessing import Process
t1 = Process(target=calculate_partial_sum, args=(0, 12000))
t2 = Process(target=calculate_partial_sum, args=(12001, 24000))
start = time.time()
t1.start()
t2.start()
while t1.is_alive() or t2.is_alive():
time.sleep(0.1)
end = time.time()
print(f'The 2 processes took {(end-start):.2f} seconds')
The 2 processes took 10.52 seconds
import time
from multiprocessing import Process
t1 = Process(target=calculate_partial_sum, args=(0, 6000))
t2 = Process(target=calculate_partial_sum, args=(6001, 12000))
t3 = Process(target=calculate_partial_sum, args=(12001, 18000))
t4 = Process(target=calculate_partial_sum, args=(18001, 24000))
start = time.time()
t1.start()
t2.start()
t3.start()
t4.start()
while t1.is_alive() or t2.is_alive() or t3.is_alive() or t4.is_alive():
time.sleep(0.1)
end = time.time()
print(f'The 4 processes took {(end-start):.2f} seconds')
The 4 processes took 6.62 seconds
Макар и не с много, виждаме подобрение във времето при скалирането от 1 процес на 2 процеса, и от 2 на 4 - това забавяне идва от предимно от баланса на задачите - втория процес има по-сложна задача, затова му отнема повече време.
Комуникация между процеси#
Имаме няколко варианта за комуникация между процесите - Queue, pipe, споделена памет и т.нар. “сървърен процес”
Queue#
Можем да създадем опашка, която да бъде споделена между процеси - тя е синхронизирана, т.е. няма риск от race conditions.
import random
from multiprocessing import Process, Queue
def put_in_the_queue(q):
q.put(random.randint(0, 10))
q = Queue()
p1 = Process(target=put_in_the_queue, args=(q, ))
p2 = Process(target=put_in_the_queue, args=(q, ))
p1.start()
p2.start()
p1.join()
p2.join()
print(f'Amount of items in the Queue: {q.qsize()}')
while q.qsize() > 0:
print(f'Item in the Queue: {q.get()}')
Amount of items in the Queue: 2
Item in the Queue: 10
Item in the Queue: 4
Pipe#
Вместо опашка, която е обща за всички процеси/нишки, можем да използваме “тръба” (пайп), свързана към два процеса/нишки. Тя позволява двупосочна комуникация между процеси. Извикването на Pipe ни връща два обекта - пайп през който можем да изпращаме данни, и пайп през който можем да получаваме данни. С подаване на duplex аргумента със стойност True, двата пайпа получават възможността за четене и писане. Чрез методите send и recv може да изпращаме и получаваме съобщения по Pipe-а. recv блокира процеса/нишката, докато не се получи съобщение, което да се обработи.
import time
from multiprocessing import Process, Pipe, connection
def wait_and_send(pipe: connection.Connection):
print("Sending a message")
time.sleep(1)
pipe.send(42)
def receive_and_print(pipe: connection.Connection):
msg = pipe.recv()
print(f"Received a message: {msg}")
send_pipe, receive_pipe = Pipe()
p1 = Process(target=wait_and_send, args=(send_pipe, ))
p2 = Process(target=receive_and_print, args=(receive_pipe, ))
p1.start()
p2.start()
p1.join()
p2.join()
Sending a message
Received a message: 42
asyncio#
https://docs.python.org/3.10/library/asyncio.html#module-asyncio
Една от по-интересните (и полезни) функционалности в Python, е поддържката на async/await синтаксиса. Благодарение на него, можем да реализираме асинхронни IO операции. Модулът asyncio ни дава множество функции и обекти свързани с async IO в Python.
Какво са async IO и coroutines ?#
Async IO е вид конкурентно изпълнение на функции - асинхроността ни дава възможност да “спрем” изпълнението на дадена функция в един момент докато те изчакват някакъв ресурс, и да дадем контрола на друга такава функция. Тези функции, които имат възможността да бъдат спирани и продължавани се наричат корутини (coroutines). Основната разлика с многонишковото и многопроцесорното програмиране е, че тук използваме един процес и една нишка.
Async IO ни позволява да изпълняваме coroutines в т.нар. event loop - докато една coroutine чака, event loop-а може да пусне друга да се изпълнява.
Нека разгледаме една проста функция, и нейния coroutine еквивалент:
def add(x: int, y: int) -> int:
return x + y
async def add(x: int, y: int) -> int:
return x + y
За да изпълним дадената функция, трябва да я добавим към текущия event loop. Може да си представим event loop-а като безкраен цикъл, който изпълнява нашите функции в дадено време.
От нас се изисква да пуснем event loop-а, да добавим нашата coroutine в списъка за изпълнение и да спрем loop-а след като функцията ни е изпълнена - това може да бъде изпълнено чрез ключовата дума await
import asyncio
async def add(x: int, y: int) -> int:
return x + y
result = await add(2, 3)
print(result)
5
С помощта на await, ние казваме - добави тази функция в event loop-а, и когато се изпълни, вземи резултата, и го принтирай на екрана.
Нека разгледаме следните две функции - fast_hi и slow_hi - едната ще изчака 1 секунда, и ще изпише “Hi”, а другата ще изчака 3 секунди, преди да изпише “Hi”
import asyncio
async def fast_hi():
print("Starting fast hi")
await asyncio.sleep(1)
print("Fast said hi")
async def slow_hi():
print("Starting slow hi")
await asyncio.sleep(3)
print("Slow said hi")
await fast_hi()
await slow_hi()
Starting fast hi
Fast said hi
Starting slow hi
Slow said hi
В текущото изпълнение, двете ни функции работят последователно. Но можем да ги накараме да работят конкурентно, като ги превърнем в задачи Task.
import asyncio
async def fast_hi():
print("Starting fast hi")
await asyncio.sleep(1)
print("Fast said hi")
async def slow_hi():
print("Starting slow hi")
await asyncio.sleep(3)
print("Slow said hi")
slow_task = asyncio.create_task(slow_hi())
fast_task = asyncio.create_task(fast_hi())
await slow_task
await fast_task
Starting slow hi
Starting fast hi
Fast said hi
Slow said hi
За превръщането на coroutine в Task използваме asyncio.create_task. При текущата подредба, slow_task започва първа изпълнението си, и достига до 3-секундното чакане. Вместо да седи и да не прави нищо, изпълнението се сменя върху fast_task, докато изчакваме нашия 3-секунден sleep да приключи.
До момента трябваше ръчно да създаваме coroutines и техните Task-ове. Но всъщност ние можем и динамично да правим извиквания към вече дефинираната ни coroutine. За целта използваме asyncio.gather. Нека имаме coroutine, който има за цел да умножи две числа и да върне резултата. Също така, нека имаме даден наброй входа. Искаме да извършим операциите върху тях асинхронно.
import asyncio
async def multiply(a: int, b: int) -> int:
return a * b
inputs = [(8, 2), (1, 12), (-2, -4), (3, -3)]
coroutines = [multiply(first, second) for first, second in inputs]
results = await asyncio.gather(*coroutines)
print(results)
[16, 12, 8, -9]
asyncio е обширна тема, която няма да покрием изцяло в курса. Оставяме няколко полезни линка, за тези които искат да навлязат по-надълбоко с asyncio.
Примери#
Пример 1#
Нека имаме функция, която умножава две матрици.
Нека напишем функция, която умножава две матрици паралелно. Нека използваме multiprocessing библиотеката за целта.
import time
def timeit():
def wrapper(func):
def inner(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f'The function took {(end-start):.2f} seconds')
return result
return inner
return wrapper
@timeit()
def multiply_matrix(a: list[list[int]], b: list[list[int]]) -> list[list[int]]:
size_of_a = (len(a), len(a[0]))
size_of_b = (len(b), len(b[0]))
if size_of_a[1] != size_of_b[0]:
raise ValueError("The matrixes cannot be multiplied")
m, n, p = size_of_a[0], size_of_a[1], size_of_b[1]
result = [[0 for _ in range(p)] for _ in range(m)]
for i in range(m):
for j in range(p):
result[i][j] = sum(a[i][k] * b[k][j] for k in range(n))
return result
Решение на пример 1#
from multiprocessing import Array, Process
@timeit()
def multithreaded_multiply_matrix(a: list[list[int]], b: list[list[int]]) -> list[list[int]]:
size_of_a = (len(a), len(a[0]))
size_of_b = (len(b), len(b[0]))
if size_of_a[1] != size_of_b[0]:
raise ValueError("The matrixes cannot be multiplied")
m, n, p = size_of_a[0], size_of_a[1], size_of_b[1]
result = Array('i', m * p)
threads = [Process(target=multiply_row, args=(result, n, p, i, a, b)) for i in range(m)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
return [result[i*p:(i+1)*p] for i in range(m)]
def multiply_row(shared_memory: Array, n: int, p: int, i: int, a: list[list[int]], b: list[list[int]]):
for j in range(p):
target_index = i * p + j
shared_memory[target_index] = sum(a[i][k] * b[k][j] for k in range(n))
from random import randint
m, n, p = 400, 400, 400
value_range = (0, 10)
a = [[randint(*value_range) for _ in range(n)] for _ in range(m)]
b = [[randint(*value_range) for _ in range(p)] for _ in range(n)]
res_1 = multiply_matrix(a, b)
res_2 = multithreaded_multiply_matrix(a, b)
The function took 3.87 seconds
The function took 0.99 seconds
Пример 2#
Нека напишем функция parallel_file_search, която приема път до файл, низ по който търсим и брой на нишките, които ще използваме за търсенето. Функцията трябва да запише редовете, които съдържат низа в нов файл.
Файла трябва да се раздели на N части, в които да се търси паралелно.
Казваме, че един ред съдържа търсения низ, ако той се среща в него.
Решение на пример 2#
from multiprocessing import Process, Semaphore
def search_in_lines(lines: list[str], to_search: str, output_path: str, semaphore: Semaphore):
for line in lines:
if to_search in line:
results.append(line)
@timeit()
def parallel_file_search(input_path: str, to_search: str, n: int, output_path: str) -> list[str]:
with open(input_path, encoding='utf-8') as input_file_descriptor:
amount_of_lines = len(input_file_descriptor.readlines())
chunk_size = amount_of_lines // n
regions = [(i * chunk_size, (i+1) * chunk_size) for i in range(n - 1)] + [((n - 1) * chunk_size, amount_of_lines + 1)]
procs = [Process(target=search_string_in_file, args=(to_search, input_path, region, output_path)) for region in regions]
for proc in procs:
proc.start()
for proc in procs:
proc.join()
def search_string_in_file(string: str, file_path: str, region: tuple[int, int], output_file_path: str, semaphore: Semaphore):
results = []
start, end = region
with open(file_path, encoding='utf-8') as input_file_descriptor:
for line_number, line in enumerate(input_file_descriptor):
if start <= line_number < end:
column = line.find(string)
while column != -1:
results.append(line.strip())
column = line.find(string, column+1)
semaphore.acquire()
with open(output_file_path, encoding='utf-8', mode='w+') as output_file_descriptor:
for result in results:
output_file_descriptor.write(result + '\n')
semaphore.release()